"100"Modelling interlude: Tristan da Cunha outbreak & the SEITL model
Estimated time: 2-2.5 hours
Introduction
Entering the stochastic tier: You’ve completed the core sessions with deterministic ODE models. This session introduces stochastic simulation and a new dataset (Tristan da Cunha) that we’ll use for the rest of the course. Fitting resumes in Particle Filters.
This session focuses on modelling rather than fitting (fitting returns in the Particle Filters and Particle MCMC sessions). The aim is to familiarise you with a real dataset - the Tristan da Cunha outbreak - and a new model called SEITL. This dataset and model serve as the running example for all remaining sessions.
As you will read below, the SEITL model has been proposed as a mechanistic explanation for a two-wave influenza A/H3N2 epidemic that occurred on the remote island of Tristan da Cunha in 1971. Given the small population size of this island (284 inhabitants), random effects at the individual level may have had important consequences at the population level. For instance, even if the distribution of the infectious period is the same for all islanders, some islanders will stay infectious longer than others just by chance and might therefore produce more secondary cases. This phenomenon is called demographic stochasticity and it could have played a significant role in the dynamics of the epidemic on Tristan da Cunha.
Unsurprisingly, to account for demographic stochasticity we need a stochastic model. However, as you will see in this session and the following, simulating and fitting a stochastic model is much more computationally costly than doing so for a deterministic model. This is why it is important to understand when and why you need to use stochastic or deterministic models. In fact, we hope that by the end of the day you’ll be convinced that both approaches are complementary.
Finally, because this session is devoted to modelling rather than fitting, we thought it was useful to show you how you can make your model biologically more realistic by using distributions for the time spent in each compartment that are more realistic than the exponential distribution.
Objectives
In this session you will:
- Familiarise yourselves with the structure of the SEITL model and try to guess its parameter values from the literature.
- Compare deterministic and stochastic simulations in order to explore the role of demographic stochasticity in the dynamics of the SEITL model.
- Use a more realistic distribution for the time spent in one of the compartment and assess its effect on the shape of the epidemic.
ImportantStochastic models produce different results each run
Unlike deterministic models, stochastic simulations give different outputs every time you run them - even with identical parameters. This is a feature, not a bug: it reflects the real randomness in small populations.
What this means for you: - Your plots will look different from your neighbour’s (and from any solutions we show) - Running the same code twice gives different trajectories - This is expected and correct behaviour
We set Random.seed!(1234) for reproducibility within a session, but the key insight is that stochastic variability between simulations is precisely what makes inference harder and more interesting.
NoteCourse roadmap
This session marks a transition in the course. We move from general inference methods (MCMC, diagnostics, model checking) to applying them to a specific scientific question: explaining the two-wave Tristan da Cunha outbreak.
The remaining sessions build on the SEITL/SEIT4L models introduced here:
- Particle Filters: Estimating likelihoods for stochastic models
- Particle MCMC: Full Bayesian inference using particle filters
- Observation Models: Comparing likelihood-based and likelihood-free inference
- Variational Inference (optional): Fast approximate inference for real-time applications
- Universal Differential Equations (optional): Learning unknown mechanisms with neural networks
Setup
Source file
The source file of this session is located at sessions/seitl.qmd.
Load libraries
using Random ## for random numbers
using Distributions ## for probability distributions
using DifferentialEquations ## for differential equations
# JumpProcesses.jl is an alternative for stochastic simulation - we implement Gillespie manually here
using DataFrames ## for data frames
using Plots ## for plots
using StatsPlots ## for statistical plots
using Turing ## for probabilistic programming and MCMC
using CSV ## for CSV file reading
using DrWatsonInitialisation
We set a random seed for reproducibility.
Random.seed!(1234)TaskLocalRNG()But first of all, let’s have a look at the data.
Tristan da Cunha outbreak

Tristan da Cunha is a volcanic island in the South Atlantic Ocean. It has been inhabited since the \(19^{th}\) century and in 1971, the 284 islanders were living in the single village of the island: Edinburgh of the Seven Seas. Whereas the internal contacts were typical of close-knit village communities, contacts with the outside world were infrequent and mostly due to fishing vessels that occasionally took passengers to or from the island. These ships were often the cause of introduction of new diseases into the population. As for influenza, no outbreak had been reported since an epidemic of A/H1N1 in 1954. In this context of a small population with limited immunity against influenza, an unusual epidemic occurred in 1971, 3 years after the global emergence of the new subtype A/H3N2.
On August 13, a ship returning from Cape Town landed five islanders on Tristan da Cunha. Three of them had developed acute respiratory disease during the 8-day voyage and the other two presented similar symptoms immediately after landing. Various family gatherings welcomed their disembarkation and in the ensuing days an epidemic started to spread rapidly throughout the whole island population. After three weeks of propagation, while the epidemic was declining, some islanders developed second episodes of illness and a second peak of cases was recorded. The epidemic faded out after this second wave and lasted a total of 59 days. Despite the lack of virological data, serological evidence indicates that all episodes of illness were due to influenza A/H3N2.
Among the 284 islanders, 273 (96%) experienced at least one episode of illness and 92 (32%) experienced two, which is remarkable for influenza. Unfortunately, only 312 of the 365 attacks (85%) are known to within a single day of accuracy and constitute the dataset reported by Mantle & Tyrrell in 1973.
The dataset of daily incidence can be loaded and plotted as follows:
# Load Tristan da Cunha data
# Alternatively, you can load directly from GitHub:
# flu_tdc_url = "https://raw.githubusercontent.com/sbfnk/mfiidd.julia/main/data/flu_tdc_1971.csv"
# flu_tdc = CSV.read(download(flu_tdc_url), DataFrame)
flu_tdc = CSV.read(joinpath(@__DIR__, "..", "data", "flu_tdc_1971.csv"), DataFrame)
# Display first few rows
first(flu_tdc, 6)6×3 DataFrame
| Row | date | time | obs |
|---|---|---|---|
| Date | Int64 | Int64 | |
| 1 | 1971-08-13 | 1 | 0 |
| 2 | 1971-08-14 | 2 | 1 |
| 3 | 1971-08-15 | 3 | 0 |
| 4 | 1971-08-16 | 4 | 10 |
| 5 | 1971-08-17 | 5 | 6 |
| 6 | 1971-08-18 | 6 | 32 |
# Plot daily observed incidence
scatter(
flu_tdc.time, flu_tdc.obs,
xlabel = "Time (days)", ylabel = "Daily incidence",
label = "Observed cases", markersize = 4, color = :red,
title = "Tristan da Cunha 1971 Influenza Outbreak"
)
SEITL model
One possible explanation for the rapid influenza reinfections reported during this two-wave outbreak is that following recovery from a first infection, some islanders did not develop long-term protective immunity and remained fully susceptible to reinfection by the same influenza strain that was still circulating. This can be modelled as follows:
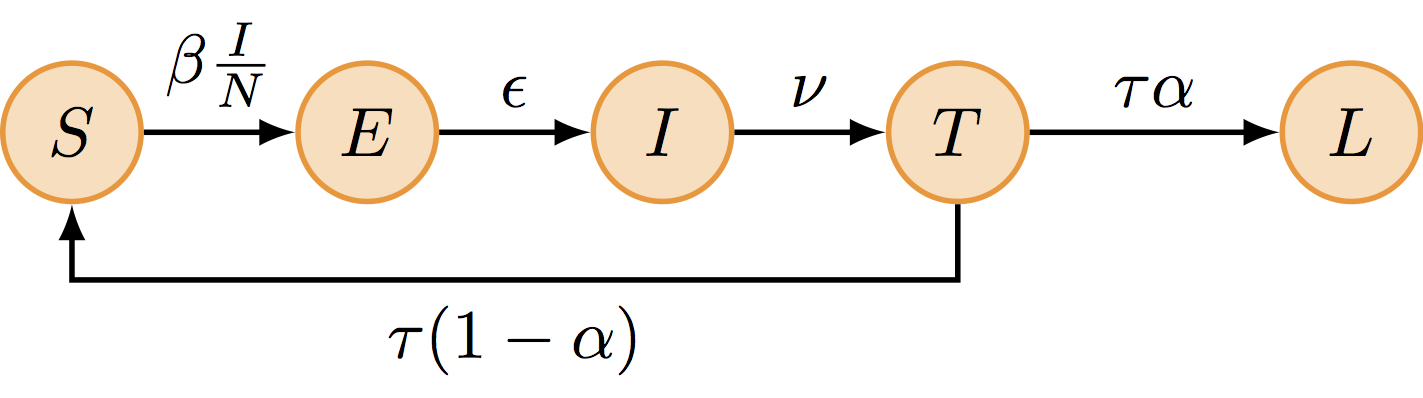
The SEITL model can be described with five states (S, E, I, T and L) and five parameters:
- basic reproductive number (\(R_0\))
- latent period (\(D_\mathrm{lat}\))
- infectious period (\(D_\mathrm{inf}\))
- temporary-immune period (\(D_\mathrm{imm}\))
- probability of developing a long-term protection (\(\alpha\)).
and the following deterministic equations:
\[ \begin{cases} \begin{aligned} \frac{\mathrm{d}S}{\mathrm{d}t} &= - \beta S \frac{I}{N} + (1-\alpha) \tau T\\ \frac{\mathrm{d}E}{\mathrm{d}t} &= \beta S \frac{I}{N} - \epsilon E\\ \frac{\mathrm{d}I}{\mathrm{d}t} &= \epsilon E - \nu I\\ \frac{\mathrm{d}T}{\mathrm{d}t} &= \nu I - \tau T\\ \frac{\mathrm{d}L}{\mathrm{d}t} &= \alpha \tau T\\ \end{aligned} \end{cases} \]
where \(\beta=R_0/D_\mathrm{inf}\), \(\epsilon=1/D_\mathrm{lat}\), \(\nu = 1/D_\mathrm{inf}\), \(\tau=1/D_\mathrm{imm}\) and \(N = S + E + I + L + T\) is constant.
It can be shown that there is an analogy between the deterministic equations and the algorithm that performs stochastic simulations of the model. In that sense, the deterministic equations are a description of the stochastic model, too.
In order to fit the SEITL model to the Tristan da Cunha dataset we need to add one state variable and one parameter to the model:
- The dataset represents daily incidence counts: we need to create a \(6^\mathrm{th}\) state variable - called \(\mathrm{Inc}\) - to track the daily number of new cases. Assuming that new cases are reported when they become symptomatic and infectious, we have the following equation for the new state variable: \[ \frac{d\mathrm{Inc}}{dt} = \epsilon E \]
- The dataset is incomplete: only 85% of the cases were reported. In addition, we need to account for potential under-reporting of asymptomatic cases. We assume that the data were reported according to a Poisson process with reporting rate \(\rho\). Since this reporting rate is unknown (we can only presume that it should be below 85% due to reporting errors) we will include it as an additional parameter.
Parameter values and initial state
Based on the description of the outbreak above and the information below found in the literature, can you think of one or more set(s) of values for the parameters and initial state of the model?
- The \(R_0\) of influenza is commonly estimated to be around 2. However, it can be significantly larger in close-knit communities with exceptional contact configurations.
- Both the average latent and infectious periods for influenza have been estimated around 2 days each.
- The down-regulation of the cellular response is completed on average 15 days after symptom onset.
- Serological surveys have shown that the seroconversion rate to influenza (probability of developing antibodies) is around 80%. However, it is likely that not all seroconverted individuals acquire a long-term protective against reinfection.
- Between 20 and 30% of the infections with influenza are asymptomatic.
- There is very limited cross-immunity between influenza viruses A/H1N1 and A/H3N2.
TipHint: Reasonable parameter ranges
Based on the literature above, here are reasonable starting guesses:
| Parameter | Reasoning | Suggested range |
|---|---|---|
| R_0 | Typically ~2 for influenza, but higher in close-knit communities | 4-10 |
| D_lat | Latent period ~2 days | 1-3 |
| D_inf | Infectious period ~2 days | 1-4 |
| D_imm | Cellular response ~15 days post-symptom | 10-20 |
| α | Seroconversion ~80%, but not all develop long-term immunity | 0.4-0.8 |
| ρ | <85% reporting, minus asymptomatic (20-30%) | 0.5-0.7 |
These are just starting points. The inference will refine them.
Deterministic vs Stochastic simulations
NoteTwo independent modelling choices
This session explores two separate decisions that can be combined independently:
- Simulation method: deterministic (ODEs) vs stochastic (Gillespie) — controls whether we model individual-level randomness
- Compartment durations: exponential (SEITL) vs Erlang (SEIT4L) — controls how realistic the waiting times are
These are orthogonal: you can have a deterministic SEIT4L or a stochastic SEITL. We cover all four combinations below, but the key point is that each choice addresses a different biological question.
Now, try to assess whether the SEITL model can reproduce the two-wave outbreak of Tristan da Cunha with your guess values for the initial state and the parameters. This will give you the opportunity to compare the deterministic and stochastic model. We suggest to start with the deterministic model and then move on to the stochastic model but feel free to proceed in a different way.
Deterministic simulations
Let’s define the SEITL model for deterministic simulation:
"""
SEITL model ODE function for deterministic simulation.
States: S (susceptible), E (exposed), I (infectious),
T (temporary immunity), L (long-term immunity), Inc (daily incidence)
Parameters: R_0, D_lat, D_inf, α, D_imm, ρ
"""
function seitl_ode!(du, u, p, t)
# Unpack parameters
R_0, D_lat, D_inf, α, D_imm = p
# Convert to rates
β = R_0 / D_inf
ϵ = 1.0 / D_lat
ν = 1.0 / D_inf
τ = 1.0 / D_imm
# Unpack states
S, E, I, T, L, Inc = u
# Total population
N = S + E + I + T + L
# ODEs
du[1] = -β * S * I / N + (1 - α) * τ * T # dS/dt
du[2] = β * S * I / N - ϵ * E # dE/dt
du[3] = ϵ * E - ν * I # dI/dt
du[4] = ν * I - τ * T # dT/dt
du[5] = α * τ * T # dL/dt
du[6] = ϵ * E # dInc/dt (cumulative incidence)
end
"""
Simulate the deterministic SEITL model.
"""
function simulate_seitl_deterministic(θ, init_state, times)
# Parameters (without ρ which is only for observation process)
params = [θ[:R_0], θ[:D_lat], θ[:D_inf], θ[:α], θ[:D_imm]]
# Initial state with Inc = 0
u0 = [init_state[:S], init_state[:E], init_state[:I],
init_state[:T], init_state[:L], 0.0]
# Solve ODE
prob = ODEProblem(seitl_ode!, u0, (times[1], times[end]), params)
sol = solve(prob, Tsit5(), saveat=times)
# Convert to DataFrame
state_names = [:S, :E, :I, :T, :L, :Inc_cumulative]
sol_matrix = reduce(hcat, sol.u)'
df = DataFrame(sol_matrix, state_names)
df[!, :time] = sol.t
# Convert cumulative incidence to daily incidence
df[!, :Inc] = [0.0; diff(df.Inc_cumulative)]
return df
end
"""
Turing model for SEITL - enables both simulation and inference.
When unconditioned, use for prior predictive simulation.
When conditioned with | (; obs = data), use for inference (in later sessions).
"""
@model function seitl_model(times, init_state, n_obs)
# Deliberately wide priors — we want the data to drive inference
# rather than our prior beliefs. These ranges are generous enough
# to include all plausible parameter values for influenza.
R_0 ~ Uniform(1.0, 50.0)
D_lat ~ Uniform(0.1, 10.0)
D_inf ~ Uniform(0.1, 15.0)
α ~ Uniform(0.0, 1.0)
D_imm ~ Uniform(1.0, 50.0)
ρ ~ Uniform(0.0, 1.0)
# Create parameter dictionary
θ = Dict(:R_0 => R_0, :D_lat => D_lat, :D_inf => D_inf,
:α => α, :D_imm => D_imm, :ρ => ρ)
# Simulate trajectory
traj = simulate_seitl_deterministic(θ, init_state, times)
# Likelihood
lambdas = [max(ρ * traj.Inc[i], 1e-10) for i in 1:n_obs]
obs ~ arraydist(Poisson.(lambdas))
return traj
endMain.Notebook.seitl_modelNow let’s try some parameter values based on the literature:
# First guess based on the literature
θ_guess = Dict(
:R_0 => 2.0,
:D_lat => 2.0,
:D_inf => 2.0,
:α => 0.9,
:D_imm => 13.0,
:ρ => 0.85
)
# Initial state
# 5 initial infected from the ship
# L = 30: although cross-immunity between H1N1 (1954) and H3N2 (1971) is limited,
# some islanders may have pre-existing immunity from other exposures or
# non-specific resistance. This is a rough guess — inference will refine it.
init_state_guess = Dict(
:S => 250.0,
:E => 0.0,
:I => 4.0,
:T => 0.0,
:L => 30.0
)
# Simulate
times = collect(0.0:1.0:60.0)
traj = simulate_seitl_deterministic(θ_guess, init_state_guess, times)
# Show first few rows
first(traj, 10)10×8 DataFrame
| Row | S | E | I | T | L | Inc_cumulative | time | Inc |
|---|---|---|---|---|---|---|---|---|
| Float64 | Float64 | Float64 | Float64 | Float64 | Float64 | Float64 | Float64 | |
| 1 | 250.0 | 0.0 | 4.0 | 0.0 | 30.0 | 0.0 | 0.0 | 0.0 |
| 2 | 247.071 | 2.28068 | 2.97746 | 1.61109 | 30.0593 | 0.654475 | 1.0 | 0.654475 |
| 3 | 244.561 | 3.37136 | 2.9543 | 2.89721 | 30.216 | 2.09152 | 2.0 | 1.43704 |
| 4 | 241.931 | 4.14454 | 3.28718 | 4.17691 | 30.4605 | 3.97574 | 3.0 | 1.88422 |
| 5 | 238.985 | 4.87384 | 3.77937 | 5.56485 | 30.7969 | 6.22965 | 4.0 | 2.25391 |
| 6 | 235.634 | 5.646 | 4.37251 | 7.11264 | 31.2347 | 8.85704 | 5.0 | 2.62739 |
| 7 | 231.824 | 6.48755 | 5.05044 | 8.85227 | 31.7861 | 11.8873 | 6.0 | 3.03028 |
| 8 | 227.514 | 7.40334 | 5.80855 | 10.809 | 32.4654 | 15.3569 | 7.0 | 3.46962 |
| 9 | 222.676 | 8.38771 | 6.64382 | 13.0046 | 33.2883 | 19.3021 | 8.0 | 3.94519 |
| 10 | 217.292 | 9.42869 | 7.54986 | 15.4575 | 34.272 | 23.754 | 9.0 | 4.45187 |
Plotting code
# Plot the simulated incidence against the data
p = plot(title = "SEITL Model: Deterministic Simulation",
xlabel = "Time (days)", ylabel = "Cases")
# Plot simulated incidence
plot!(p, traj.time, traj.Inc, label = "Simulated", linewidth = 2, color = :blue)
# Overlay real data
scatter!(p, flu_tdc.time, flu_tdc.obs,
label = "Observed data", markersize = 4, color = :red)
plot!(p)
You can visualise all state variables by plotting them:
Plotting code
# Plot all state variables
plot(
plot(traj.time, traj.S, label = "S", title = "Susceptible", ylabel = "Count"),
plot(traj.time, traj.E, label = "E", title = "Exposed", ylabel = "Count"),
plot(traj.time, traj.I, label = "I", title = "Infectious", ylabel = "Count"),
plot(traj.time, traj.T, label = "T", title = "Temporary immunity", ylabel = "Count"),
plot(traj.time, traj.L, label = "L", title = "Long-term immunity", ylabel = "Count"),
plot(traj.time, traj.Inc, label = "Inc", title = "Daily incidence", ylabel = "Count"),
layout = (3, 2), size = (800, 600), legend = false
)
Note that although the simulation of the trajectory is deterministic, the observation process is stochastic (Poisson with reporting rate \(\rho\)). You can generate multiple observation replicates:
"""
Generate observed incidence using Poisson observation process.
"""
function generate_observations(traj, ρ)
obs = [rand(Poisson(ρ * inc)) for inc in traj.Inc]
return obs
end
# Generate 100 replicates of observations
p = plot(title = "Observation Process Variability",
xlabel = "Time (days)", ylabel = "Cases")
for i in 1:100
obs = generate_observations(traj, θ_guess[:ρ])
plot!(p, traj.time, obs, alpha = 0.2, color = :lightblue, label = "")
end
# Overlay real data
scatter!(p, flu_tdc.time, flu_tdc.obs,
label = "Observed data", markersize = 4, color = :red)
plot!(p)
Using Turing for simulation
You’ve just seen how to simulate the model by directly calling the simulation function with specific parameter values. However, since we’ve defined a Turing @model, we can also sample from the prior predictive distribution. This is useful when we want to explore the range of behaviours the model can produce before seeing any data.
# Sample from the prior predictive distribution
# This samples parameter values from the priors and simulates trajectories
# Generate 5 trajectories using the Turing model
# Without conditioning, the model samples parameters from priors and simulates
p = plot(title = "Prior Predictive Simulations",
xlabel = "Time (days)", ylabel = "Cases")
for i in 1:5
# Sample parameters from priors
seitl_prior = seitl_model(times, init_state_guess, length(times))
params = rand(seitl_prior).data
# Create parameter dictionary and simulate
θ = Dict(:R_0 => params.R_0, :D_lat => params.D_lat, :D_inf => params.D_inf,
:α => params.α, :D_imm => params.D_imm, :ρ => params.ρ)
traj = simulate_seitl_deterministic(θ, init_state_guess, times)
plot!(p, traj.time, traj.Inc, alpha = 0.5, label = "")
end
scatter!(p, flu_tdc.time, flu_tdc.obs,
label = "Observed data", markersize = 4, color = :red)
plot!(p)
Notice how the same @model definition can be used for both simulation (here) and inference (in the Particle MCMC session). This unified approach means you only need to write the model once.
Now, take 5 minutes to explore the dynamics of the model for different parameter and initial state values. In particular, try different values for \(R_0\in[2-15]\) and \(\alpha\in[0.3-1]\). For which values of \(R_0\) and \(\alpha\) do you get a decent fit?
You should find that it is hard to capture all the data-points with the deterministic model. We will now test if this can be better reproduced with a stochastic model which explicitly accounts for the discrete nature of individuals.
Stochastic simulations
The stochastic simulation uses the Gillespie algorithm, which simulates individual events (infections, recoveries) as random occurrences. Unlike ODEs which give smooth trajectories, this captures the inherent randomness in small populations. Each event is sampled from the possible transitions weighted by their rates, and waiting times between events follow exponential distributions.
The model has the following transitions:
| Transition | Rate | Effect |
|---|---|---|
| S → E | \(\beta S I / N\) | S-1, E+1 |
| E → I | \(\epsilon E\) | E-1, I+1 (count as new case) |
| I → T | \(\nu I\) | I-1, T+1 |
| T → S | \((1-\alpha) \tau T\) | T-1, S+1 |
| T → L | \(\alpha \tau T\) | T-1, L+1 |
NoteImplementation: Gillespie algorithm (click to expand)
"""
SEITL stochastic model using Gillespie algorithm.
Simulates day-by-day, tracking daily incidence directly.
"""
function simulate_seitl_stochastic(θ, init_state, times)
R_0, D_lat, D_inf, α, D_imm = θ[:R_0], θ[:D_lat], θ[:D_inf], θ[:α], θ[:D_imm]
β = R_0 / D_inf
ϵ = 1.0 / D_lat
ν = 1.0 / D_inf
τ = 1.0 / D_imm
# State: [S, E, I, T, L] - no cumulative incidence needed
state = Float64[init_state[:S], init_state[:E], init_state[:I],
init_state[:T], init_state[:L]]
# Stoichiometry: how each transition changes [S, E, I, T, L]
stoich = [
[-1, 1, 0, 0, 0], # S → E
[0, -1, 1, 0, 0], # E → I
[0, 0, -1, 1, 0], # I → T
[1, 0, 0, -1, 0], # T → S
[0, 0, 0, -1, 1] # T → L
]
function rates(s)
S, E, I, T, L = s
N = S + E + I + T + L
[β*S*I/N, ϵ*E, ν*I, (1-α)*τ*T, α*τ*T]
end
# Gillespie step: simulate one time unit, return daily incidence
function gillespie_step!(s, dt)
t, daily_inc = 0.0, 0
while t < dt
r = rates(s)
total_rate = sum(r)
total_rate ≤ 0 && break
τ_wait = randexp() / total_rate
t + τ_wait > dt && break
t += τ_wait
# Select event
cum, rnd, event = 0.0, rand() * total_rate, 0
for i in 1:5
cum += r[i]
if rnd ≤ cum
event = i
break
end
end
# Apply transition
for j in 1:5
s[j] += stoich[event][j]
end
# Track E→I transitions as new cases
event == 2 && (daily_inc += 1)
end
daily_inc
end
# Simulate day-by-day
n_days = length(times)
results = DataFrame(time=times, S=zeros(n_days), E=zeros(n_days),
I=zeros(n_days), T=zeros(n_days), L=zeros(n_days),
Inc=zeros(n_days))
for (i, t) in enumerate(times)
# Record state at start of day
results.S[i], results.E[i], results.I[i] = state[1], state[2], state[3]
results.T[i], results.L[i] = state[4], state[5]
# Simulate one day and record incidence
if i < n_days
results.Inc[i+1] = gillespie_step!(state, times[i+1] - t)
end
end
return results
endMain.Notebook.simulate_seitl_stochastic
TipCode explainer
- Stoichiometry matrix: Each row defines how compartments change for one transition type (e.g.,
[-1, 1, 0, 0, 0]means S decreases by 1 and E increases by 1 for infection) rates(s): Computes the current rate of each transition based on compartment sizesgillespie_step!: Simulates one day by repeatedly: (1) drawing an exponential waiting time, (2) selecting which event occurs proportional to rates, (3) applying the state changerandexp() / total_rate: Waiting time to next event follows Exp(total_rate)- Event selection: Cumulative sum trick to select event with probability proportional to its rate
event == 2: E→I transitions are counted as new cases (daily incidence)
NoteComing from R?
In R, the GillespieSSA2 and adaptivetau packages provide Gillespie simulation. The odin and dust packages from the MRC Centre offer a more performant framework for stochastic compartmental models. Here we implement Gillespie manually to show the algorithm clearly, but Julia’s JumpProcesses.jl package provides a production-quality implementation.
"""
Turing model for stochastic SEITL - enables both simulation and inference.
This version uses the Gillespie algorithm for demographic stochasticity.
"""
@model function seitl_stochastic_model(times, init_state, n_obs)
# Priors
R_0 ~ Uniform(1.0, 50.0)
D_lat ~ Uniform(0.1, 10.0)
D_inf ~ Uniform(0.1, 15.0)
α ~ Uniform(0.0, 1.0)
D_imm ~ Uniform(1.0, 50.0)
ρ ~ Uniform(0.0, 1.0)
# Create parameter dictionary
θ = Dict(:R_0 => R_0, :D_lat => D_lat, :D_inf => D_inf,
:α => α, :D_imm => D_imm, :ρ => ρ)
# Simulate stochastic trajectory
traj = simulate_seitl_stochastic(θ, init_state, times)
# Likelihood
lambdas = [max(ρ * traj.Inc[i], 1e-10) for i in 1:n_obs]
obs ~ arraydist(Poisson.(lambdas))
return traj
endMain.Notebook.seitl_stochastic_modelNow let’s run stochastic simulations with the same parameters:
# Run a single stochastic simulation
traj_stoch = simulate_seitl_stochastic(θ_guess, init_state_guess, times)
# Plot
p = plot(title = "SEITL Model: Stochastic Simulation",
xlabel = "Time (days)", ylabel = "Cases")
plot!(p, traj_stoch.time, traj_stoch.Inc, label = "Simulated (stochastic)",
linewidth = 2, color = :blue)
scatter!(p, flu_tdc.time, flu_tdc.obs,
label = "Observed data", markersize = 4, color = :red)
plot!(p)
Run multiple stochastic replicates to see variability:
# Generate multiple stochastic trajectories with the same parameters
# This shows the variability from demographic stochasticity
p = plot(title = "SEITL Model: 50 Stochastic Replicates",
xlabel = "Time (days)", ylabel = "Cases")
for i in 1:50
traj_rep = simulate_seitl_stochastic(θ_guess, init_state_guess, times)
plot!(p, traj_rep.time, traj_rep.Inc, alpha = 0.3,
color = :lightblue, label = "")
end
scatter!(p, flu_tdc.time, flu_tdc.obs,
label = "Observed data", markersize = 4, color = :red)
plot!(p)
Note
Just like with the deterministic model, you can use the Turing @model for prior predictive checks by sampling parameters from priors (without conditioning on data). The same @model definitions will be used for inference in the Particle Filters and Particle MCMC sessions — condition with | (; obs = data) when fitting, leave unconditioned when simulating. See the unified approach callout at the end of this session for the full pattern.
TipExercise: Explore stochastic SEITL dynamics
What differences do you notice between stochastic and deterministic simulations? Can you make any conclusions on the role of demographic stochasticity on the dynamics of the SEITL model?
Now we make this model a bit more realistic.
Exponential vs Erlang distributions
So far, we have assumed that the time spent in each compartment follows an exponential distribution, because by assuming transitions happen at constant rates we have implied that the process is memoryless. Although mathematically convenient, this property is not realistic for many biological processes such as the contraction of the cellular response.
In order to include a memory effect, it is common practice to replace the exponential distribution by an Erlang distribution. This distribution is parametrised by its mean \(m\) and shape \(k\) and can be modelled by \(k\) consecutive sub-stages, each being exponentially distributed with mean \(m/k\).
As illustrated below the flexibility of the Erlang distribution ranges from the exponential (\(k=1\)) to Gaussian-like (\(k>>1\)) distributions.

We propose to extend the SEITL by replacing the single T compartment with 4 sub-stages (k=4). Why 4? This is a pragmatic choice from the original Camacho et al. (2011) paper: k=4 gives a bell-shaped distribution that is more realistic than the exponential (k=1), while keeping the model small enough to fit efficiently. The “Going further” section at the end invites you to explore other values of k.
The extended model looks as follows:

SEIT4L model implementation
"""
SEIT4L model: SEITL with T compartment split into 4 stages (Erlang-4 distribution).
"""
function seit4l_ode!(du, u, p, t)
# Unpack parameters
R_0, D_lat, D_inf, α, D_imm = p
# Convert to rates
β = R_0 / D_inf
ϵ = 1.0 / D_lat
ν = 1.0 / D_inf
τ = 4.0 / D_imm # Rate through each T sub-stage (4 stages total)
# Unpack states: S, E, I, T1, T2, T3, T4, L, Inc
S, E, I, T1, T2, T3, T4, L, Inc = u
# Total population
N = S + E + I + T1 + T2 + T3 + T4 + L
# ODEs
du[1] = -β * S * I / N + (1 - α) * τ * T4 # dS/dt
du[2] = β * S * I / N - ϵ * E # dE/dt
du[3] = ϵ * E - ν * I # dI/dt
du[4] = ν * I - τ * T1 # dT1/dt
du[5] = τ * T1 - τ * T2 # dT2/dt
du[6] = τ * T2 - τ * T3 # dT3/dt
du[7] = τ * T3 - τ * T4 # dT4/dt
du[8] = α * τ * T4 # dL/dt
du[9] = ϵ * E # dInc/dt
end
"""
Simulate the deterministic SEIT4L model.
"""
function simulate_seit4l_deterministic(θ, init_state, times)
params = [θ[:R_0], θ[:D_lat], θ[:D_inf], θ[:α], θ[:D_imm]]
# Initial state with Inc = 0 and T split into 4 stages
u0 = [init_state[:S], init_state[:E], init_state[:I],
init_state[:T1], init_state[:T2], init_state[:T3], init_state[:T4],
init_state[:L], 0.0]
prob = ODEProblem(seit4l_ode!, u0, (times[1], times[end]), params)
sol = solve(prob, Tsit5(), saveat=times)
# Convert to DataFrame
state_names = [:S, :E, :I, :T1, :T2, :T3, :T4, :L, :Inc_cumulative]
sol_matrix = reduce(hcat, sol.u)'
df = DataFrame(sol_matrix, state_names)
df[!, :time] = sol.t
df[!, :Inc] = [0.0; diff(df.Inc_cumulative)]
return df
end
"""
Turing model for SEIT4L - enables both simulation and inference.
This version uses an Erlang-4 distribution for the T compartment.
"""
@model function seit4l_model(times, init_state, n_obs)
# Priors
R_0 ~ Uniform(1.0, 50.0)
D_lat ~ Uniform(0.1, 10.0)
D_inf ~ Uniform(0.1, 15.0)
α ~ Uniform(0.0, 1.0)
D_imm ~ Uniform(1.0, 50.0)
ρ ~ Uniform(0.0, 1.0)
# Create parameter dictionary
θ = Dict(:R_0 => R_0, :D_lat => D_lat, :D_inf => D_inf,
:α => α, :D_imm => D_imm, :ρ => ρ)
# Simulate trajectory
traj = simulate_seit4l_deterministic(θ, init_state, times)
# Likelihood
lambdas = [max(ρ * traj.Inc[i], 1e-10) for i in 1:n_obs]
obs ~ arraydist(Poisson.(lambdas))
return traj
endMain.Notebook.seit4l_model
TipExercise: Understand the SEIT4L code
How does the code above implement the Erlang distribution for the \(T\) compartment? What changes from the SEITL version?
Now compare the dynamics of the SEITL and SEIT4L models. Use your best guess from the previous section for the parameters. Note that although SEITL and SEIT4L share the same parameters, their state variables differ so you need to modify the initial state of SEIT4L accordingly.
# Initial state for SEIT4L (need to split T into 4 stages)
init_state_4l = Dict(
:S => 250.0,
:E => 0.0,
:I => 4.0,
:T1 => 0.0,
:T2 => 0.0,
:T3 => 0.0,
:T4 => 0.0,
:L => 30.0
)
# Try with better parameter values that produce two waves
θ_better = Dict(
:R_0 => 10.0,
:D_lat => 2.0,
:D_inf => 2.0,
:α => 0.5,
:D_imm => 13.0,
:ρ => 0.7
)
# Simulate both models
traj_seitl = simulate_seitl_deterministic(θ_better, init_state_guess, times)
traj_seit4l = simulate_seit4l_deterministic(θ_better, init_state_4l, times)
# Plot comparison
p = plot(title = "SEITL vs SEIT4L", xlabel = "Time (days)", ylabel = "Cases")
plot!(p, traj_seitl.time, traj_seitl.Inc,
label = "SEITL (exponential T)", linewidth = 2, color = :blue)
plot!(p, traj_seit4l.time, traj_seit4l.Inc,
label = "SEIT4L (Erlang-4 T)", linewidth = 2, color = :green)
scatter!(p, flu_tdc.time, flu_tdc.obs,
label = "Observed data", markersize = 4, color = :red)
plot!(p)
Can you notice any differences? If so, which model seems to provide the best fit? Do you understand why the shape of the epidemic changes when you use the Erlang distribution for the \(T\) compartment?
NoteModel comparison: a preview
We now have multiple mechanistic models that could explain the two-wave pattern:
- SEITL: Exponential duration in T compartment (memoryless)
- SEIT4L: Erlang-4 duration in T compartment (more realistic timing)
Both encode the same biological hypothesis (temporary immunity followed by potential reinfection), but make different assumptions about the distribution of time spent in temporary immunity. The original Camacho et al. (2011) paper compared these and other variants using information criteria (DIC) and found that SEIT4L provided a better fit.
In the Particle Filters and Particle MCMC sessions, we’ll fit both models to data and compare them.
NoteFrom simulation to inference: the unified Turing approach
Throughout this session, you’ve defined models using the @model macro with the pattern:
@model function my_model(times, init_state, n_obs)
# 1. Define priors
R_0 ~ Uniform(1.0, 50.0)
# ... other parameters
# 2. Simulate trajectory
traj = simulate_function(θ, init_state, times)
# 3. Likelihood
obs ~ arraydist(Poisson.(λ))
return traj
endThe obs variable is not a function argument — it’s a random variable defined by the ~ statements. To supply observed data, use the | (condition) operator:
model = my_model(times, init_state, length(data)) | (; obs = data)This unified structure enables both:
- Simulation (this session): Call
rand(my_model(times, init_state, n_obs))to sample from the prior predictive distribution (no conditioning —obsis sampled) - Inference (next session): Call
sample(model, NUTS(), 1000)wheremodelis conditioned on data (the exact sampler choice depends on the model — see the MCMC and Particle MCMC sessions) - Posterior prediction: Use
predict(decondition(model), chain)to generate new observations from the fitted model
You write the model once and use it for all purposes. This is the power of probabilistic programming!
TipLearning points
- Deterministic models are fast but ignore individual-level randomness
- Stochastic models capture demographic stochasticity, important for small populations
- Erlang distributions provide more realistic compartment durations than exponential
- Same parameters, different dynamics: stochastic models show variability even with fixed parameters
- Unified Turing models work for both simulation and inference
ImportantWhy we need particle filters
Fitting stochastic models is fundamentally harder than fitting deterministic ones. With a deterministic model, the same parameters always produce the same trajectory, so the likelihood is straightforward. With a stochastic model, the same parameters can produce wildly different trajectories — there is no single “expected” output to compare against.
Particle filters solve this by running many stochastic simulations simultaneously and estimating the likelihood as an average. The next session introduces this technique.
References
- Camacho et al. (2011). Explaining rapid reinfections in multiple-wave influenza outbreaks: the role of the immune response. Proc. R. Soc. B 278(1725), 3635-3643. (The original SEITL model paper - highly recommended!)
- Mantle & Tyrrell (1973). An epidemic of influenza on Tristan da Cunha. Journal of Hygiene 71(1), 89-95. (Original outbreak data)
- JumpProcesses.jl - Stochastic simulation in Julia (Gillespie algorithm and more)
- Turing.jl documentation - Probabilistic programming in Julia
Going further
- Curious about why we use the Poisson likelihood for count data? Have a look at the bottom of page 3 of this reference from Germán Rodríguez’ lecture notes on generalized linear models.
- Stochastic SEIT4L: We implemented a stochastic version of SEITL but not SEIT4L. As an exercise, try implementing
simulate_seit4l_stochasticby extending the Gillespie algorithm with additional transitions for the T1→T2→T3→T4 sub-stages. The stoichiometry matrix will need 7 transitions instead of 5. - You might wonder why we only modified the distribution of the \(T\) compartment. Indeed, wouldn’t it be more realistic to use Erlang distributions for all the other compartments? And why did we use a shape equal to 4 and not 2 or 100? Think about another variant of the SEITL model and implement it by modifying the original version in a similar way as we did for the SEIT4L model. Does it fit the data better?