Modelling interlude: Tristan da Cunha outbreak & the SEITL model
Objectives
This session will focus on modelling rather than fitting (don’t worry, we will come back to fitting on the next session). The aim of this session is to familiarise yourselves with a real data set: the Tristan da Cunha outbreak and a new model called SEITL. We felt this session was necessary as we will use this dataset and this model as a toy example to illustrate all the concepts and methods from now until the end of the course.
As you will read below, the SEITL model has been proposed as a mechanistic explanation for a two-wave influenza A/H3N2 epidemic that occurred on the remote island of Tristan da Cunha in 1971. Given the small population size of this island (284 inhabitants), random effects at the individual level may have had important consequences at the population level. For instance, even if the distribution of the infectious period is the same for all islanders, some islanders will stay infectious longer than others just by chance and might therefore produce more secondary cases. This phenomenon is called demographic stochasticity and it could have played a significant role in the dynamics of the epidemic on Tristan da Cunha.
Unsurprisingly, to account for demographic stochasticity we need a stochastic model. However, as you will see in this session and the following, simulating and fitting a stochastic model is much more computationally costly than doing so for a deterministic model. This is why it is important to understand when and why you need to use stochastic or deterministic models. In fact, we hope that by the end of the day you’ll be convinced that both approaches are complementary.
Finally, because this session is devoted to modelling rather than fitting, we thought it was useful to show you how you can make your model biologically more realistic by using distributions for the time spent in each compartment that are more realistic than the exponential distribution.
In brief, in this session you will:
- Familiarise yourselves with the structure of the SEITL model and try to guess its parameter values from the literature.
- Compare deterministic and stochastic simulations in order to explore the role of demographic stochasticity in the dynamics of the SEITL model.
- Use a more realistic distribution for the time spent in one of the compartment and assess its effect on the shape of the epidemic.
But first of all, let’s have a look at the data.
Tristan da Cunha outbreak

Tristan da Cunha is a volcanic island in the South Atlantic Ocean. It has been inhabited since the \(19^{th}\) century and in 1971, the 284 islanders were living in the single village of the island: Edinburgh of the Seven Seas. Whereas the internal contacts were typical of close-knit village communities, contacts with the outside world were infrequent and mostly due to fishing vessels that occasionally took passengers to or from the island. These ships were often the cause of introduction of new diseases into the population. As for influenza, no outbreak had been reported since an epidemic of A/H1N1 in 1954. In this context of a small population with limited immunity against influenza, an unusual epidemic occurred in 1971, 3 years after the global emergence of the new subtype A/H3N2.
On August 13, a ship returning from Cape Town landed five islanders on Tristan da Cunha. Three of them had developed acute respiratory disease during the 8-day voyage and the other two presented similar symptoms immediately after landing. Various family gatherings welcomed their disembarkation and in the ensuing days an epidemic started to spread rapidly throughout the whole island population. After three weeks of propagation, while the epidemic was declining, some islanders developed second episodes of illness and a second peak of cases was recorded. The epidemic faded out after this second wave and lasted a total of 59 days. Despite the lack of virological data, serological evidence indicates that all episodes of illness were due to influenza A/H3N2.
Among the 284 islanders, 273 (96%) experienced at least one episode of illness and 92 (32%) experienced two, which is remarkable for influenza. Unfortunately, only 312 of the 365 attacks (85%) are known to within a single day of accuracy and constitute the dataset reported by Mantle & Tyrrell in 1973.
The dataset of daily incidence can be loaded and plotted as follows:
data(fluTdc1971)
head(fluTdc1971)
## date time obs
## 1 1971-08-13 1 0
## 2 1971-08-14 2 1
## 3 1971-08-15 3 0
## 4 1971-08-16 4 10
## 5 1971-08-17 5 6
## 6 1971-08-18 6 32
# plot daily observed incidence
plotTraj(data = fluTdc1971)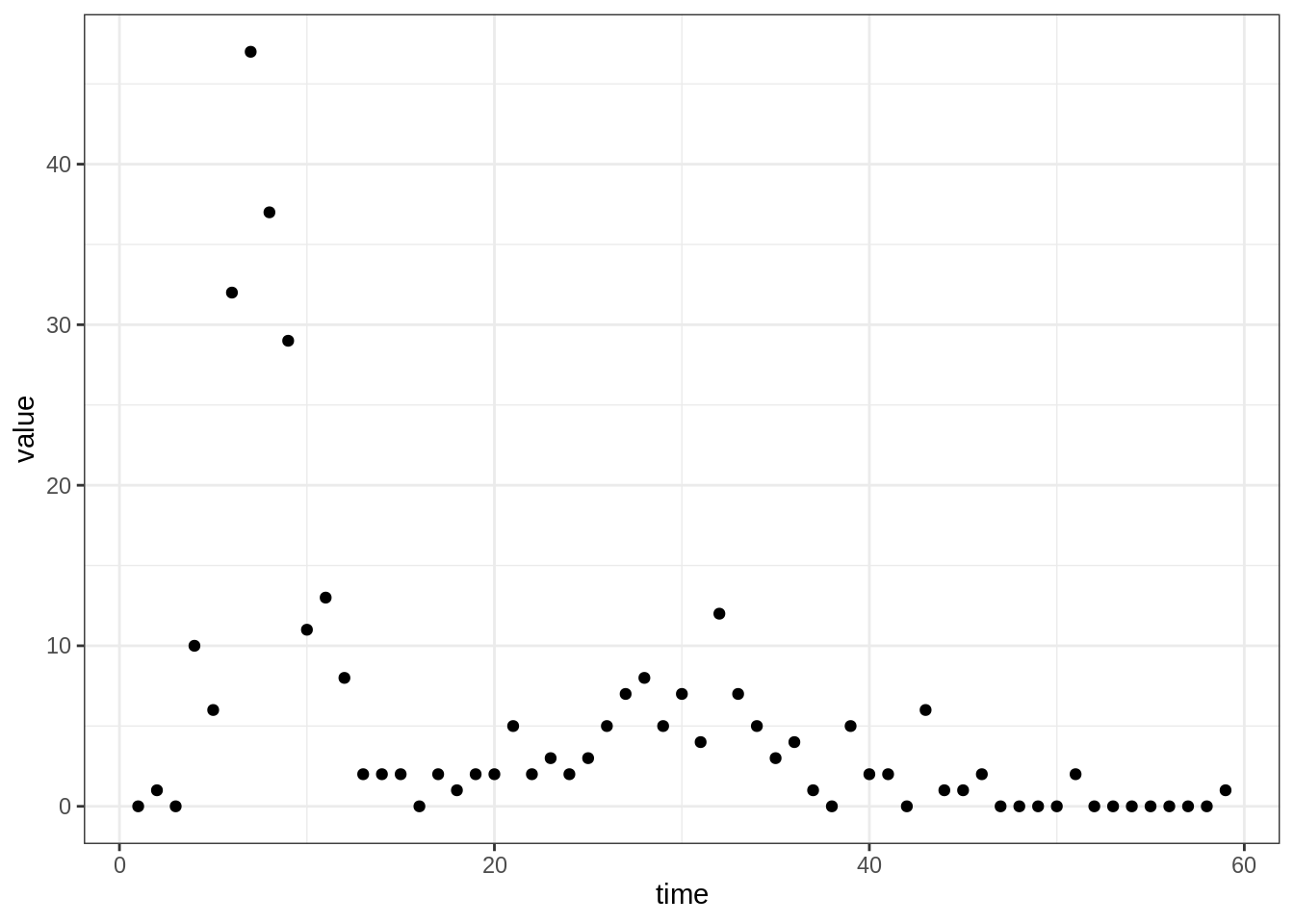
SEITL model
One possible explanation for the rapid influenza reinfections reported during this two-wave outbreak is that following recovery from a first infection, some islanders did not develop long-term protective immunity and remained fully susceptible to reinfection by the same influenza strain that was still circulating. This can be modelled as follows:
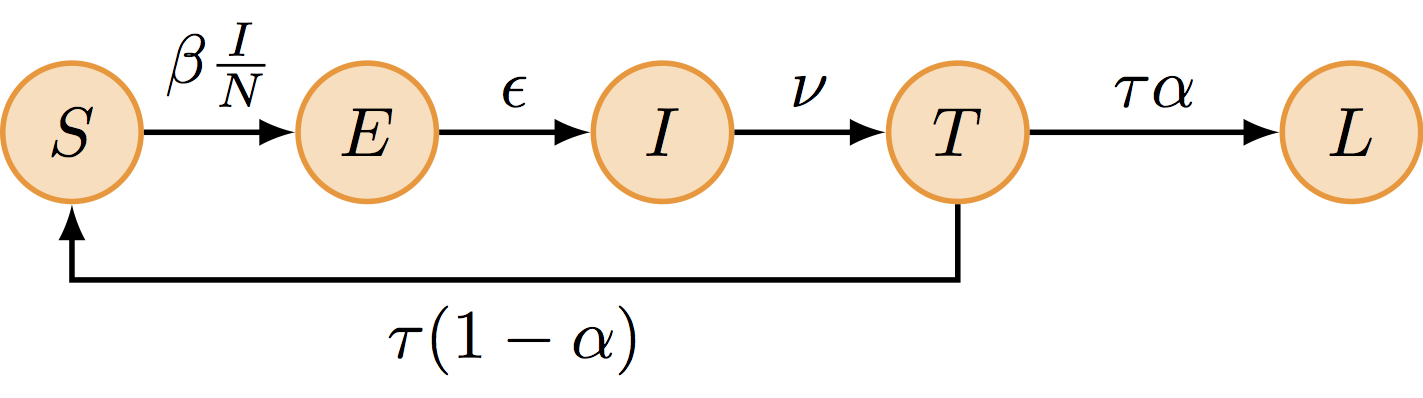
The SEITL model can be described with five states (S, E, I, T and L) and five parameters:
- basic reproductive number (\(R_0\))
- latent period (\(D_\mathrm{lat}\))
- infectious period (\(D_\mathrm{inf}\))
- temporary-immune period (\(D_\mathrm{imm}\))
- probability of developing a long-term protection (\(\alpha\)).
and the following deterministic equations:
\[ \begin{cases} \begin{aligned} \frac{\mathrm{d}S}{\mathrm{d}t} &= - \beta S \frac{I}{N} + (1-\alpha) \tau T\\ \frac{\mathrm{d}E}{\mathrm{d}t} &= \beta S \frac{I}{N} - \epsilon E\\ \frac{\mathrm{d}I}{\mathrm{d}t} &= \epsilon E - \nu I\\ \frac{\mathrm{d}T}{\mathrm{d}t} &= \nu I - \tau T\\ \frac{\mathrm{d}L}{\mathrm{d}t} &= \alpha \tau T\\ \end{aligned} \end{cases} \]
where \(\beta=R_0/D_\mathrm{inf}\), \(\epsilon=1/D_\mathrm{lat}\), \(\nu = 1/D_\mathrm{inf}\), \(\tau=1/D_\mathrm{imm}\) and \(N = S + E + I + L + T\) is constant.
It can be shown that there is an analogy between the deterministic equations and the algorithm that performs stochastic simulations of the model. In that sense, the deterministic equations are a description of the stochastic model, too.
In order to fit the SEITL model to the Tristan da Cunha dataset we need to add one state variable and one parameter to the model:
- The dataset represents daily incidence counts: we need to create a \(6^\mathrm{th}\) state variable - called \(\mathrm{Inc}\) - to track the daily number of new cases. Assuming that new cases are reported when they become symptomatic and infectious, we have the following equation for the new state variable: \[ \frac{d\mathrm{Inc}}{dt} = \epsilon E \]
- The dataset is incomplete: only 85% of the cases were reported. In addition, we need to account for potential under-reporting of asymptomatic cases. We assume that the data were reported according to a Poisson process with reporting rate \(\rho\). Since this reporting rate is unknown (we can only presume that it should be below 85% due to reporting errors) we will include it as an additional parameter.
The deterministic and stochastic SEITL models are already implemented
as two fitmodel objects called seitlDeter and
seitlStoch respectively. These can be loaded into your
R session by typing:
data(models)A brief technical note: You might be confused that we use a function
called data to load a fitmodel. However, this
was the best way to provide you with models that preserved comments in
the code of the function. Type seitlDeter$simulate, for
instance.
Take 10 minutes to look at the different elements of both
models. In particular, you might be interested in how the daily
incidence is computed in the function seitlDeter$simulate
and how the likelihood function seitlDeter$dPointObs
accounts for under-reporting.
You should also notice that seitlStoch mainly differs
from seitlDeter through the simulate function,
which replaces the deterministic equations solver by a stochastic
simulation algorithm. More precisely, this algorithm needs a list of
transitions (seitlTransitions) and a function to compute
the transition rate (seitlRateFunc). Make sure you
understand all the transitions and rates and see the analogy with the
deterministic equations.
If you are curious about how the stochastic model is simulated, you
can have a look at the code of the function
simulateModelStochastic. You will note that it calls the
function ssa.adaptivetau of the R package
adaptivetau, and then processes the returned data frame in
order to extract the state of the model at the desired observation times
given by times.
However, before doing any simulation, we need some parameter values and an initial state for the model.
Parameter values and initial state
Based on the description of the outbreak above and the information
below found in the literature, can you think of one or more set(s) of
values for the parameters (theta) and initial state
(initState) of the model?
- The \(R_0\) of influenza is commonly estimated to be around 2. However, it can be significantly larger in close-knit communities with exceptional contact configurations.
- Both the average latent and infectious periods for influenza have been estimated around 2 days each.
- The down-regulation of the cellular response is completed on average 15 days after symptom onset.
- Serological surveys have shown that the seroconversion rate to influenza (probability of developing antibodies) is around 80%. However, it is likely that not all seroconverted individuals acquire a long-term protective against reinfection.
- Between 20 and 30% of the infections with influenza are asymptomatic.
- There is very limited cross-immunity between influenza viruses A/H1N1 and A/H3N2.
Deterministic vs Stochastic simulations
Now, try to assess whether the SEITL model can reproduce the two-wave outbreak of Tristan da Cunha with your guess values for the initial state and the parameters. This will give you the opportunity to compare the deterministic and stochastic model. We suggest to start with the deterministic model and then move on to the stochastic model but feel free to proceed in a different way. Of course, if you don’t like to guess parameter values, you can still use ours.
Deterministic simulations
You can use the plotFit function you encountered in the
first practical to
generate an observation trajectory and display it against the data:
thetaBadGuess <- c(R_0 = 2, D_lat = 2, D_inf = 2, alpha = 0.9, D_imm = 13, rho = 0.85)
initStateBadGuess <- c(S = 250, E = 0, I = 4, T = 0, L = 30, Inc = 0)
plotFit(seitlDeter, thetaBadGuess, initStateBadGuess, data = fluTdc1971)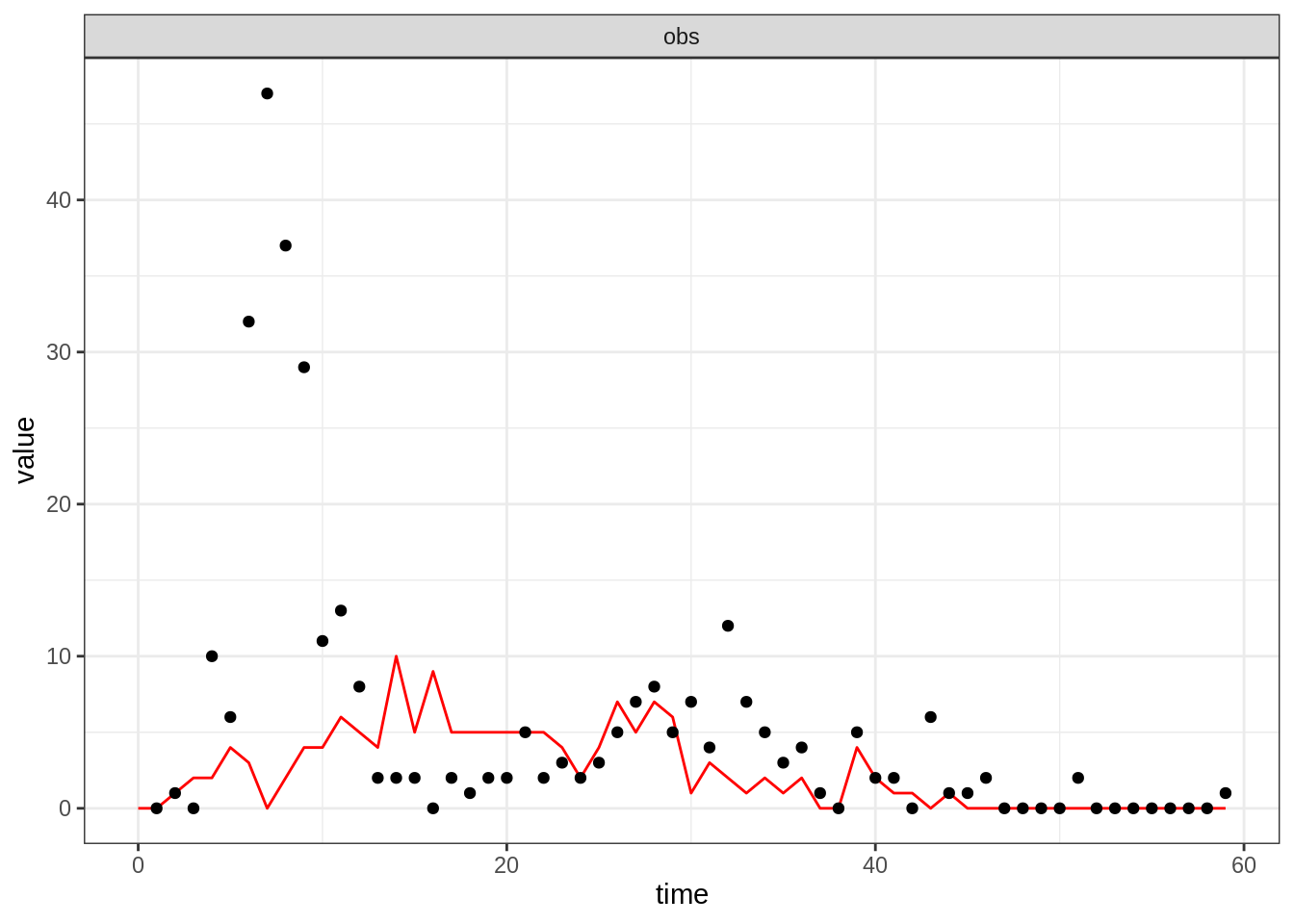
You can display all states variables (not only the sampled
observations) by passing allvars=TRUE to the
plotFit function:
plotFit(seitlDeter, thetaBadGuess, initStateBadGuess, data = fluTdc1971, allVars = TRUE)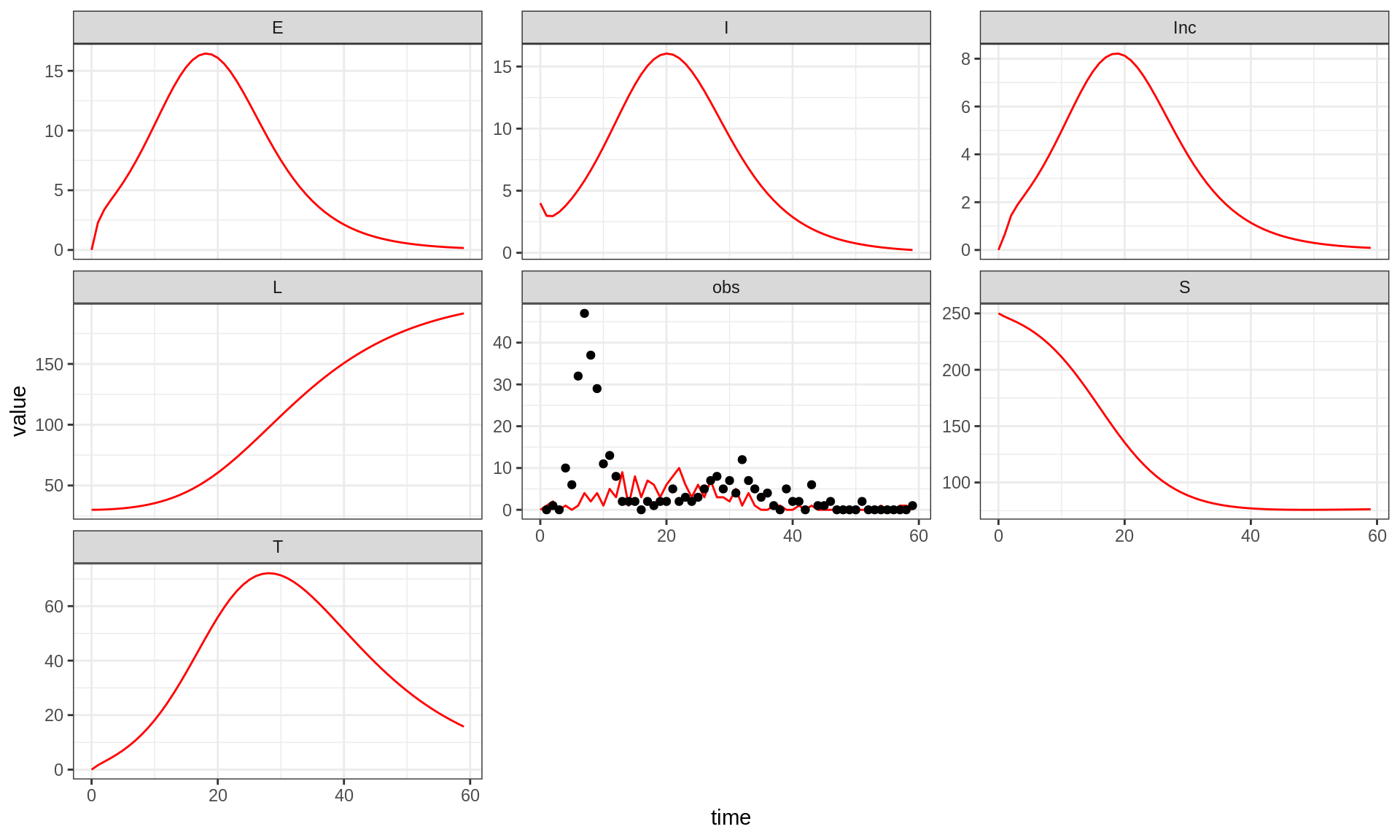
Note that although the simulation of the trajectory is deterministic,
the observation process is stochastic, hence the noisy obs
time-series. You can appreciate the variability of the observation
process by plotting several replicates (use the argument
n.replicates):
plotFit(seitlDeter, thetaBadGuess, initStateBadGuess, data = fluTdc1971, nReplicates = 100)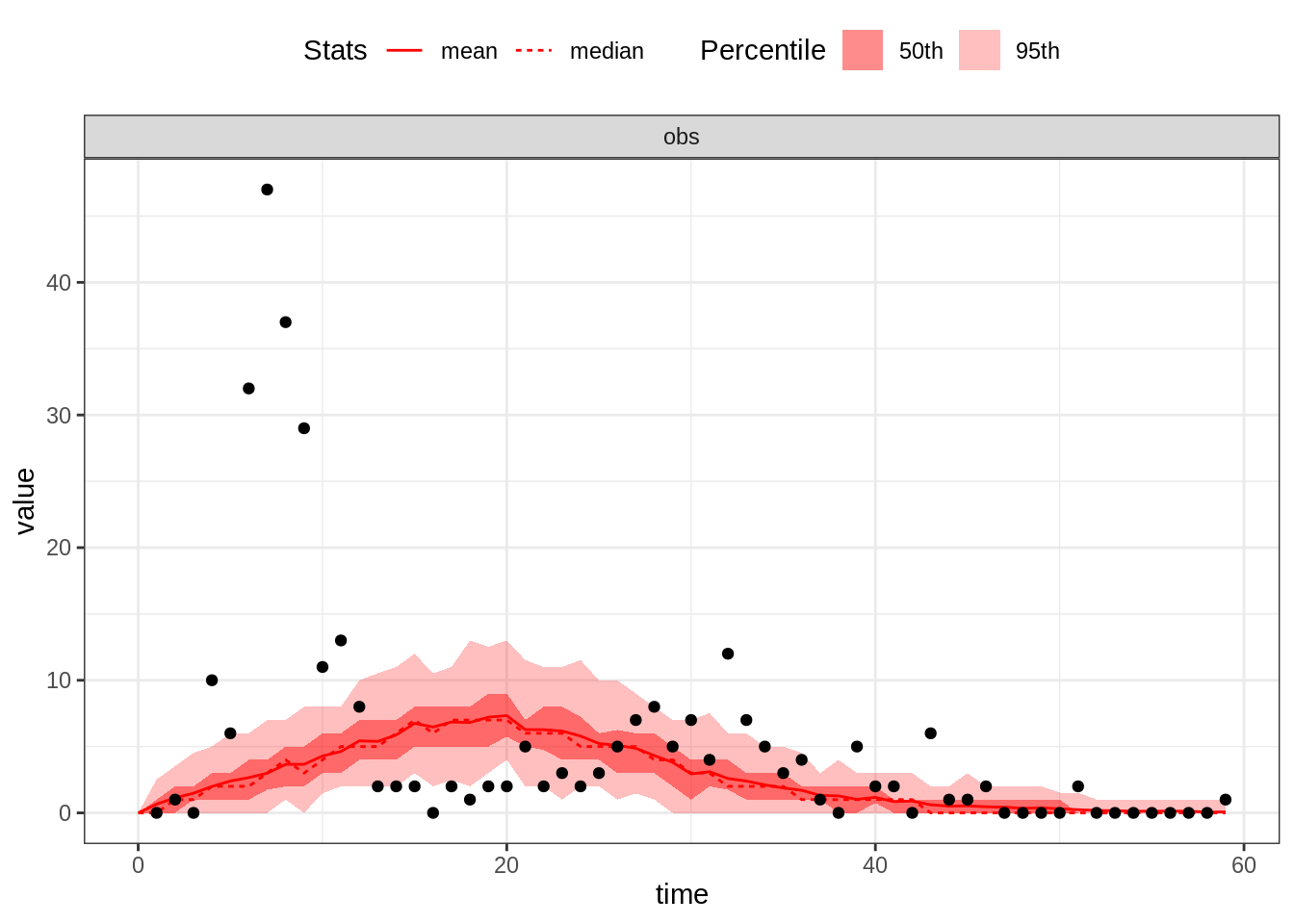
By default, this function plots the mean and the median as well as
the \(95^\mathrm{th}\) and \(50^\mathrm{th}\) percentiles of the
replicated simulations. Alternatively, you can visualise all the
simulated trajectories by passing summary=FALSE to the
plotFit function:
plotFit(seitlDeter, thetaBadGuess, initStateBadGuess, data = fluTdc1971, nReplicates = 100,
summary = FALSE)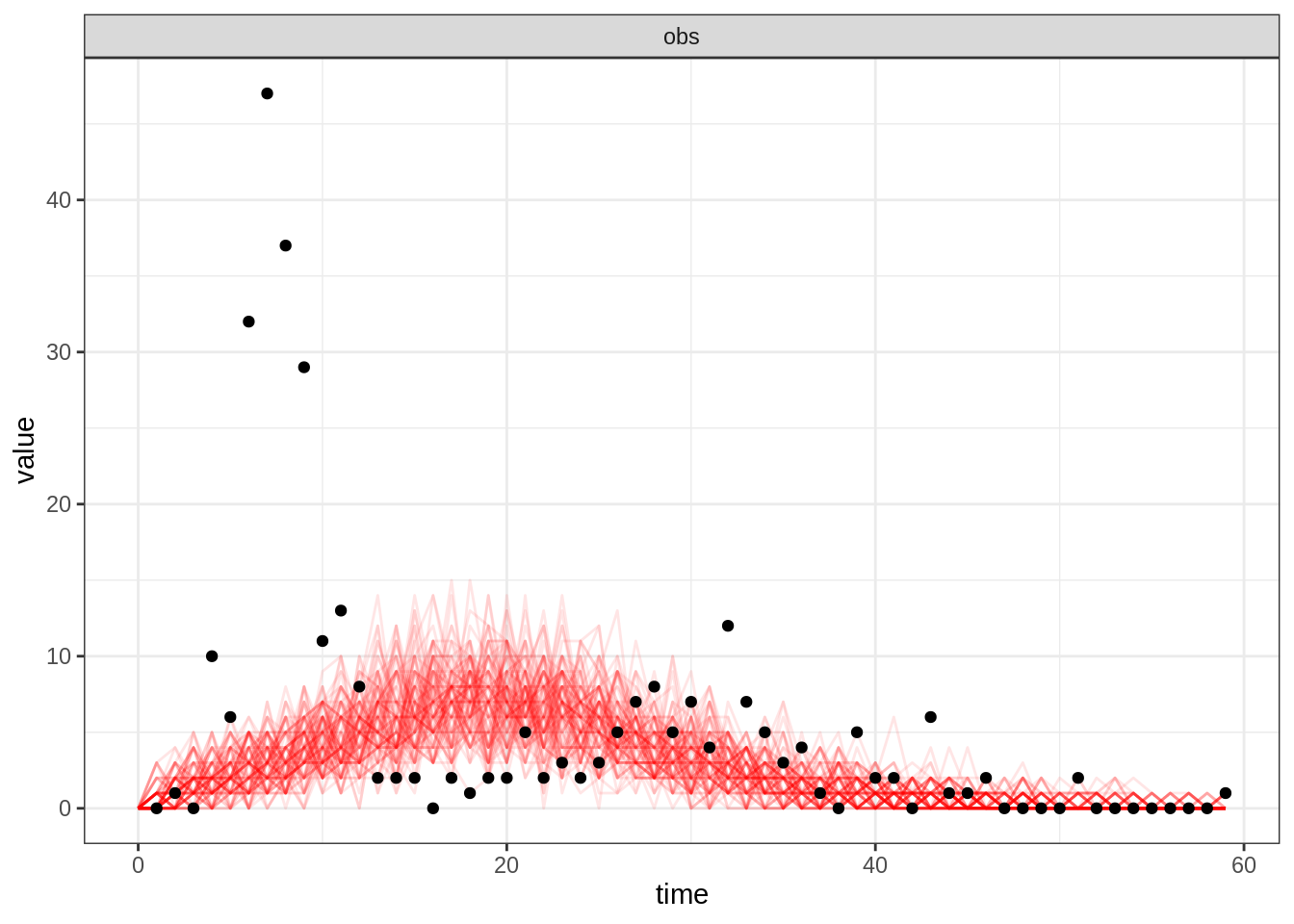
Now, take 10 minutes to explore the dynamics of the model for different parameter and initial state values. In particular, try different values for \(R_0\in[2-15]\) and \(\alpha\in[0.3-1]\). For which values of \(R_0\) and \(\alpha\) do you get a decent fit?
If you didn’t manage to get the two waves, you can have look at our example.
You should find that it is hard to capture all the data-point with the deterministic model. We will now test if this can be better reproduced with a stochastic model which explicitly accounts for the discrete nature of individuals.
Stochastic simulations
Take about 10 minutes to explore the dynamics of the
stochastic SEITL model with the function
plotFit.
Note that seitlStoch has the same
theta.names and state.names as
seitlDeter, which means that you can use the same
parameters and initial state vectors as in the previous section.
In addition, you might find useful to plot the time-series of the
extinction probability (i.e. the proportion of faded out simulations) by
specifying the infectious states to plotFit as the epidemic
will persist as long as there is at least one individual in one of these
states. You can do so by using the non.extinct argument of
plotFit (see the documentation for more details).
What differences do you notice between stochastic and deterministic simulations? Can you make any conclusions on the role of demographic stochasticity on the dynamics of the SEITL model? Otherwise you can have a look at our example.
Now, let’s try to make this model a bit more realistic.
Exponential vs Erlang distributions
So far, we have assumed that the time spent in each compartment follows an exponential distribution, because by assuming transitions happen at constant rates we have implied that the process is memoryless. Although mathematically convenient, this property is not realistic for many biological processes such as the contraction of the cellular response.
In order to include a memory effect, it is common practice to replace the exponential distribution by an Erlang distribution. This distribution is parametrised by its mean \(m\) and shape \(k\) and can be modelled by \(k\) consecutive sub-stages, each being exponentially distributed with mean \(m/k\).
{kind=link}
As illustrated below the flexibility of the Erlang distribution ranges from the exponential (\(k=1\)) to Gaussian-like (\(k>>1\)) distributions.
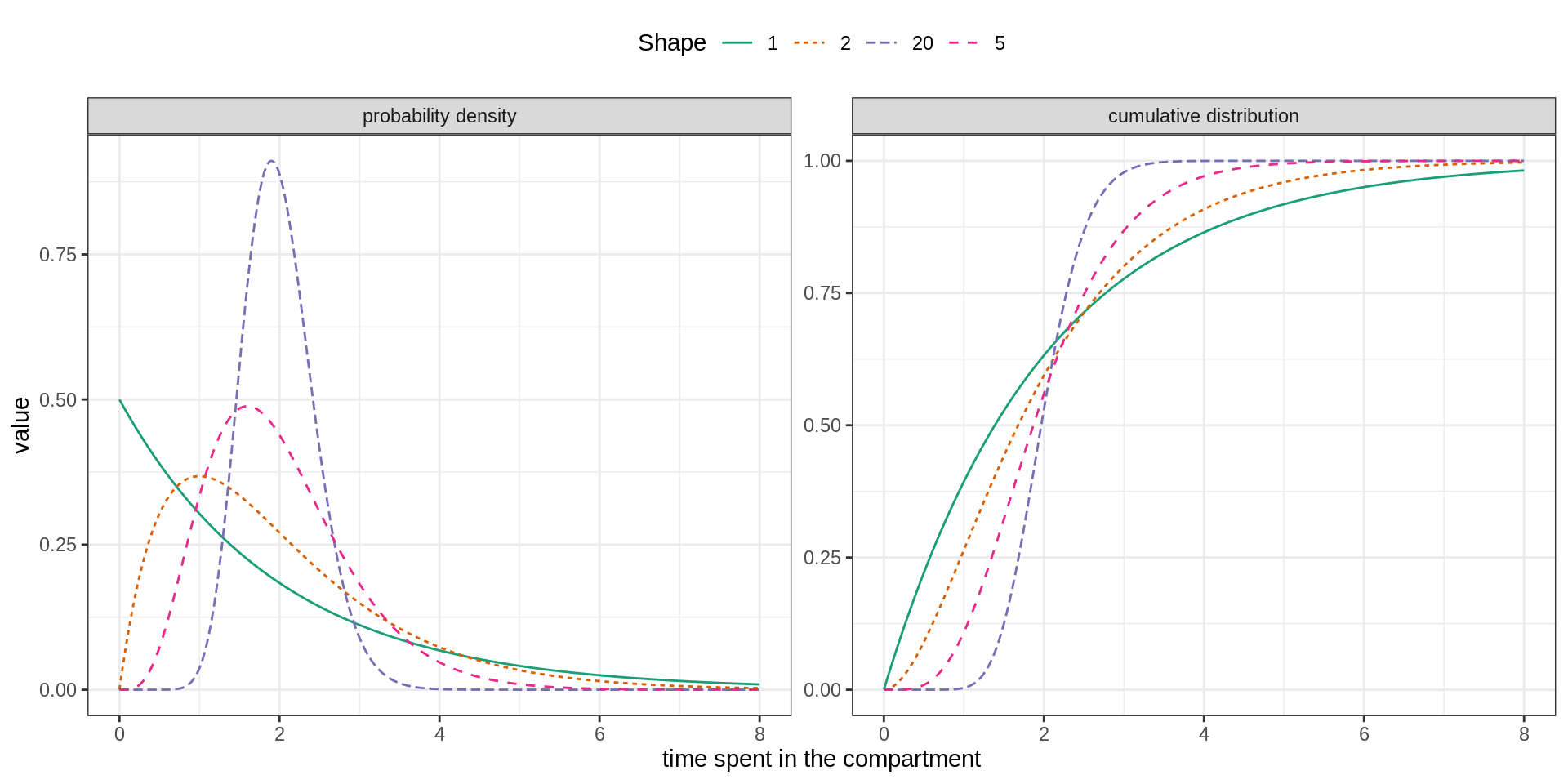
We propose to extend the SEITL as follows:

The deterministic and stochastic SEIT4L models are already
implemented as fitmodel objects called
seit4lDeter and seit4lStoch that were also
loaded into your R session with
data(models).
Take 5 minutes to have a look at the function
simulate of these SEIT4L models and make sure you
understand how the Erlang distribution for the \(T\) compartment is coded.
Now, compare the dynamics of the SEITL and SEIT4L model using
plotFit. Use your best guess from the previous section as
well as stochastic and deterministic simulations. Note that although
SEITL and SEIT4L share the same parameters, their state variables differ
so you need to modify the initState of SEIT4L
accordingly.
Can you notice any differences? If so, which model seems to provide the best fit? Do you understand why the shape of the epidemic changes when you use the Erlang distribution of the \(T\) compartment?
Again, feel free to can have a look at our example.
In the next session, you will verify your intuition by using a statistical criterion to find which model fits the best the Tristan da Cunha outbreak.
Going further
- Curious about why we use the Poisson likelihood for count data? Have a look at the bottom of page 3 of this reference from Germán Rodríguez’ lecture notes on generalized linear models.
- You might wonder why we only modified the distribution of the \(T\) compartment. Indeed, wouldn’t it be more realistic to use Erlang distributions for all the other compartments? And why did we use a shape equal to 4 and not 2 or 100? Think about another variant of the SEITL model and implement it by modifying the original version in a similar way as we did for the SEIT4L model. Does it fit the data better?
This web site and the material contained in it were originally created in support of an annual short course on Model Fitting and Inference for Infectious Disease Dynamics at the London School of Hygiene & Tropical Medicine. All material is under a MIT license. Please report any issues or suggestions for improvement on the corresponding GitHub issue tracker. We are always keen to hear about any uses of the material here, so please do get in touch using the Discussion board if you have any questions or ideas, or if you find the material here useful or use it in your own teaching.